- What's Up in AI
- Posts
- The Nvidia GTC 2026
The Nvidia GTC 2026
The most amazing tech reveals 🧑💻
What's Up in AI
June 01, 2026
In partnership with

Hey AI Geeks,
NVIDIA just wrapped GTC and Computex 2026 — and the announcements were so stacked, even people who watched it live needed a second sitting.
New chips, a new data center OS, a sneaky-smart open-weight model, and robots with fingertips more sensitive than yours. If you missed it, you're welcome.
Let's get into it. ⬇️
Stop Chasing Docs. Automate Them.
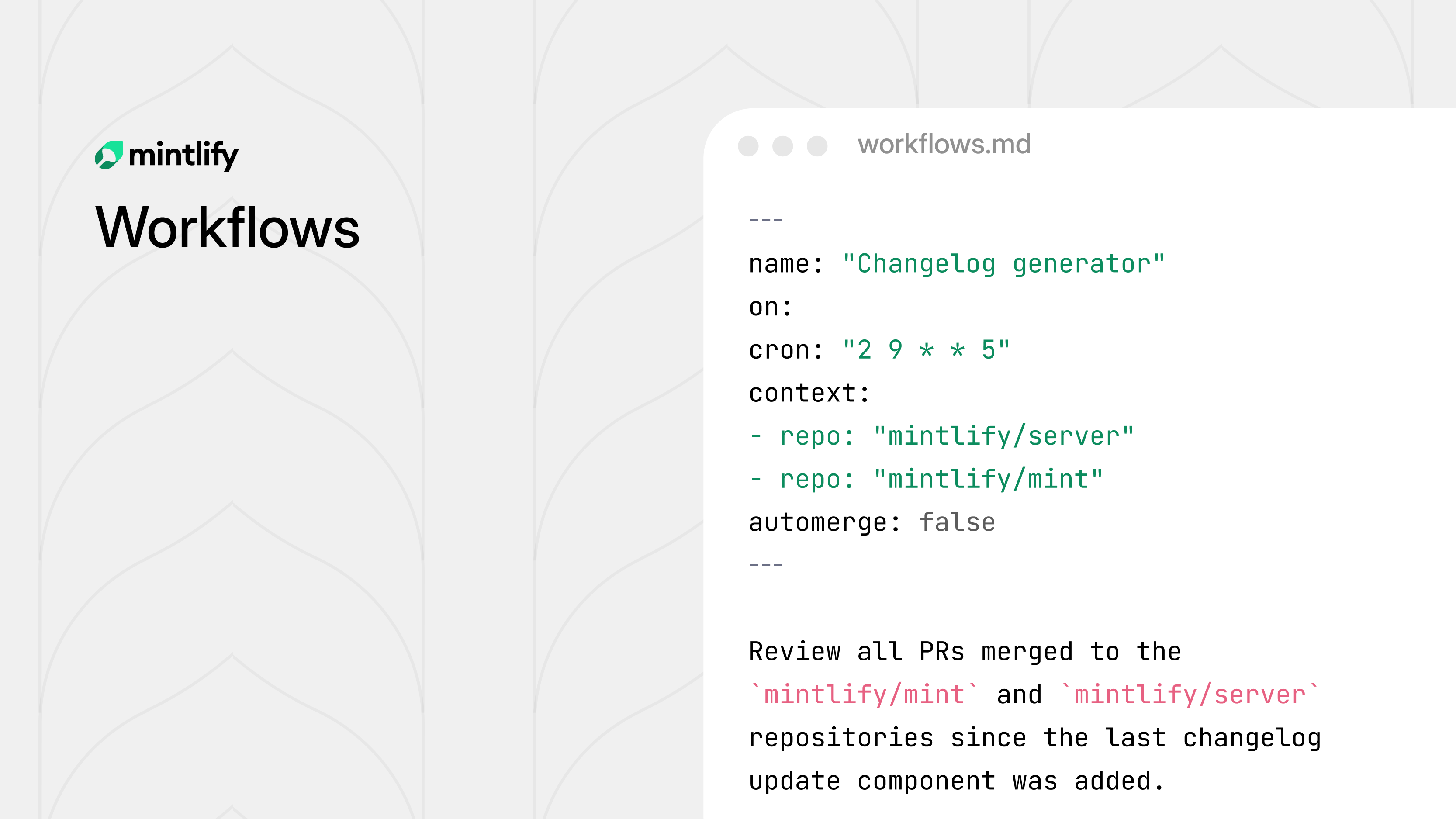
Docs piling up faster than you can write them? Same.
Every team knows the feeling — product ships, docs don't. Changelogs get forgotten. Style violations quietly accumulate. Broken links go unnoticed for months.
Mintlify's new Workflows feature fixes this. Define automation rules, and the agent handles the recurring maintenance work for you — on your schedule, by your rules.
Draft docs when a PR merges. Generate changelogs every Friday. Run a style audit on every push. Flag translation lag before it becomes a problem. Each workflow is version controlled, fully configurable, and fits into your existing review process.
You decide when it runs, what it checks, and whether changes get committed directly or opened as a pull request for review.
The result: documentation that actually keeps up with your product, without someone manually chasing it down.

NVIDIA's new server platform and it's built to solve one problem — what happens when copper wire just can't handle a million GPUs talking to each other.
They swapped copper for light. Data now travels via photonics, not electrical signals — giving you 5× better power efficiency on networking alone
The new HBM4 memory can hold massive AI "memory banks" (KV caches) at lower precision without losing quality
And server rack setup went from a 2-hour manual process to a 5-minute automated drop. That's a big deal for anyone deploying at scale
⚡ Two new ARM chips — completely different jobs
NVIDIA launched two ARM processors this cycle and they're not competing with each other at all.
Vera CPU (for data centers):
88 custom cores, can run without a GPU attached
Powers financial institutions like NYSE at 3–6× the speed of old Intel/AMD chips
Up to 1.5 TB of memory per socket
RTX Spark (for your next laptop):
10 power cores + 10 efficiency cores — uses the right ones for the right task
128 GB of unified memory shared between CPU and GPU, meaning no slow data transfers
You can run a 30 billion parameter AI model locally on a thin laptop. Let that sink in

This flew under the radar but it's genuinely clever.
Data centers waste a ton of power in the gaps between active compute cycles — NVIDIA built software to capture those "stranded watts" and redirect them
Result: 40% more GPUs running inside the same electricity budget, no new infrastructure needed
It can also sense when the city power grid is under strain and automatically t
NVIDIA's new open-weight model and it has a clever trick inside.
Total size: 120 billion parameters. Active at any one time: 12 billion. The rest are on standby and only kick in when needed
So you get big-model intelligence at small-model compute costs. That's the whole magic trick
Handles up to 1 million tokens of context — roughly a full novel's worth of text in one shot
Developers can literally dial up or dial down how hard it "thinks" per request via an API flag. Pay for effort, not just output
Moda is the AI design agent with taste

Moda is an AI design product where you prompt what you need, get a complete on-brand design, and edit every element on a full canvas.
Our viral launch hit 4.4M views in days, tens of thousands signed up, and executives at major finance and tech companies now use it.
NVIDIA's autonomous vehicle AI model, and the way it learns is the interesting part.
Instead of waiting for rare real-world events (black ice, sudden pedestrian, flooded roads), it generates those scenarios inside a simulation and trains on them first
360° vision across all cameras, built for actual reasoning not just pattern matching
Basically: the car learns to handle catastrophes before it ever touches a real road
NVIDIA open-sourced a full reference humanoid for research labs — Stanford, ETH Zurich, UC San Diego are already using it.
6 feet tall, 150 lbs, 75 total degrees of freedom (think: how many directions each joint can move)
The fingertips have over 1,000 pressure-sensing pixels each, sensitive enough to feel the difference between surfaces at 0.02 Newton resolution
The point isn't the specs — it's that every research lab now starts from the same strong foundation instead of building from scratch

That's the NVIDIA drop in full. The theme across everything is the same — they're not just making faster GPUs anymore. They're building the chips, the OS, the robots, the models, and the networking layer to connect all of it. The full stack, top to bottom.
Also here’s the full video of the event, if you wanna catch up, watch it!
And that’s a wrap!
Rate this issue and reply to this email to tell us if you liked this and would want more such deep dives! (the more specific you are, the better we can deliver!)👇️
What do you think about the issue? |
We’ll be back soon with more spicy takes on What’s Happening in AI, so stay tuned & share our newsletter with a friend! Stay Tuned! 🤖
Team What’s Up in AI